모두의 코드
씹어먹는 C++ - <10 - 3. C++ STL - 알고리즘(algorithm)>
이번 강좌에서는
람다 함수(lambda function)
정렬 알고리즘
원소 삭제 알고리즘
원소 탐색 알고리즘
등등에 대해 다룹니다.

참고 사항
그냥 C++ 의 <algorithm> 라이브러리의 함수들 목록을 보고 싶다면 여기를 클릭해주세요
안녕하세요 여러분! 이번 강좌에서는 C++ 표준 라이브러리의 알고리즘(algorithm) 라이브러리에 대해서 알아보도록 하겠습니다. 알고리즘 라이브러리는 앞선 강좌에서 이야기 했었던 대로, 컨테이너에 반복자들을 가지고 이런 저런 작업을 쉽게 수행할 수 있도록 도와주는 라이브러리 입니다.
여기서 말하는 이런 저런 작업이란, 정렬이나 검색과 같이 단순한 작업들 말고도, '이런 조건이 만족하면 컨테이너에서 지워줘' 나 '이런 조건이 만족하면 1 을 더해' 와 같은 복잡한 명령의 작업들도 알고리즘 라이브러리를 통해 수행할 수 있습니다.
우리는 알고리즘에 정의되어 있는 여러가지 함수들로 작업을 수행하게 됩니다. 이 때 이 함수들은 크게 아래와 같은 두 개의 형태를 가지고 있습니다.
template <typename Iter> void do_something(Iter begin, Iter end);
거나
template <typename Iter, typename Pred> void do_something(Iter begin, Iter end, Pred pred)
와 같은 꼴을 따르고 있습니다. 전자의 경우, 알고리즘을 수행할 반복자의 시작점과 끝점 바로 뒤를 받고, 후자의 경우 반복자는 동일하게 받되, '특정한 조건' 을 추가 인자로 받게 됩니다. 이러한 '특정한 조건'을 서술자(Predicate) 이라고 부르며 저기 Pred 에는 보통 bool 을 리턴하는 함수 객체(Functor) 를 전달하게 됩니다. (이번 강좌에서 함수 객체를 매우 편리하게 만들어주는 람다 함수에 대해 다룰 것입니다!)
정렬 (sort, stable_sort, partial_sort)
첫번째로 알고리즘 라이브러리에서 지원하는 정렬(sort) 에 대해서 알아보도록 하겠습니다. 사실 정렬이라 하면 한 가지 밖에 없을 것 같은데 정렬 알고리즘에서는 무려 3 가지 종류의 함수를 지원하고 있습니다. 이를 살펴보자면 각각 다음과 같습니다.
sort : 일반적인 정렬 함수라 생각하시면 됩니다.
stable_sort : 정렬을 하되 원소들 간의 순서를 보존합니다. 이 말이 무슨 말이냐면, 만약에 벡터에
[a, b]순으로 있었는데,a와b가 크기가 같다면 정렬을[a,b]혹은[b,a]로 할 수 있습니다. sort 의 경우 그 순서가 랜덤으로 정해집니다. 하지만 stable_sort 의 경우 그 순서를 반드시 보존합니다. 즉 컨테이너 상에서[a,b]순으로 있엇다면 정렬 시에도 (크기가 같다면)[a,b]순으로 나오게 됩니다. 이 때문에 sort 보다 좀 더 느립니다.
partial_sort : 배열의 일부분만 정렬합니다 (아래 자세히 설명하겠습니다)
그렇다면 각각의 함수들을 사용해보도록 하겠습니다!
#include <algorithm> #include <iostream> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << *begin << " "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(6); vec.push_back(4); vec.push_back(7); vec.push_back(2); std::cout << "정렬 전 ----" << std::endl; print(vec.begin(), vec.end()); std::sort(vec.begin(), vec.end()); std::cout << "정렬 후 ----" << std::endl; print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
정렬 전 ---- 5 3 1 6 4 7 2 정렬 후 ---- 1 2 3 4 5 6 7
위와 같이 잘 정렬되서 나옴을 알 수 있습니다.
sort(vec.begin(), vec.end());
sort 함수는 위와 같이 정렬할 원소의 시작 위치와, 마지막 위치 바로 뒤를 반복자로 받습니다.
참고로 sort 에 들어가는 반복자의 경우 반드시 임의접근 반복자(RandomAccessIterator) 타입을 만족해야 하므로, 우리가 봐왔던 컨테이너들 중에선 벡터와 데크만 가능하고 나머지 컨테이너는 sort 함수를 적용할 수 없습니다. (예를 들어 리스트의 경우 반복자 타입이 양방향 반복자(BidirectionalIterator) 이므로 안됩니다)
list<int> l; sort(l.begin(), l.end());
만약에 위 처럼 리스트를 정렬하려고 했다간;
컴파일 오류
Error C2784'unknown-type std::operator -(const std::move_iterator<_RanIt> &,const std::move_iterator<_RanIt2> &)': could not deduce template argument for 'const std::move_iterator<_RanIt> &' from 'std::_List_unchecked_iterator<std::_List_val<std::_List_simple_types<int>>'
위와 같은 무시무시한 컴파일 오류를 맛보게 될 것입니다!
sort 함수는 기본적으로 오름차순으로 정렬을 해줍니다. 그렇다면 만약에 내림 차순으로 정렬하고 싶다면 어떻게 할까요? 만약에 여러분이 직접 만든 타입이였다면 단순히 operator< 를 반대로 바꿔준다면 오름차순에서 내림차순이 되었겠지만, 이 경우 int 이기 때문에 이는 불가능 합니다.
하지만 앞서 대부분의 알고리즘은 3 번째 인자로 특정한 조건을 전달한다고 하였는데, 여기에 우리가 비교를 어떻게 수행할 것인지에 대해 알려주면 됩니다.
#include <algorithm> #include <iostream> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << *begin << " "; begin++; } std::cout << std::endl; } struct int_compare { bool operator()(const int& a, const int& b) const { return a > b; } }; int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(6); vec.push_back(4); vec.push_back(7); vec.push_back(2); std::cout << "정렬 전 ----" << std::endl; print(vec.begin(), vec.end()); std::sort(vec.begin(), vec.end(), int_compare()); std::cout << "정렬 후 ----" << std::endl; print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
정렬 전 ---- 5 3 1 6 4 7 2 정렬 후 ---- 7 6 5 4 3 2 1
와 같이 내림 차순으로 정렬되서 나옵니다.
struct int_compare { bool operator()(const int& a, const int& b) const { return a > b; } };
일단 위와 같이 함수 객체를 위한 구조체를 정의해주시고, 그 안에 operator() 함수를 만들어주면 함수 객체 준비는 땡입니다.
std::sort(vec.begin(), vec.end(), int_compare());
그리고 위와 같이 생성된 함수 객체를 전달하면 됩니다. 그런데 말입니다. 사실 int 나 string 과 같은 기본 타입들은 모두 < 혹은 > 연산자들이 기본으로 내장되어 있습니다. 그렇다면 굳이 그렇게 귀찮게 함수 객체를 만들 필요는 없을 것 같습니다. 템플릿도 배운 마당에 그냥
template <typename T> struct greater_comp { bool operator()(const T& a, const T& b) const { return a > b; } };
요런게 있어서 굳이 귀찮게 int 따로 string 따로 만들 필요가 없을 것 같습니다. 다행이도 functional 해더에 다음과 같은 템플릿 클래스가 존재합니다.
std::sort(vec.begin(), vec.end(), greater<int>());
저 greater 에 우리가 사용하고자 하는 타입을 넣게 되면 위와 같은 함수 객체를 자동으로 만들어줍니다. 물론 그 해당하는 타입의 > 연산자가 존재해야겠지요. int 의 경우 기본 타입이기 때문에 당연히 존재합니다.
다음으로 살펴볼 함수는 partial_sort 함수 입니다.
#include <algorithm> #include <iostream> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << *begin << " "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(6); vec.push_back(4); vec.push_back(7); vec.push_back(2); std::cout << "정렬 전 ----" << std::endl; print(vec.begin(), vec.end()); std::partial_sort(vec.begin(), vec.begin() + 3, vec.end()); std::cout << "정렬 후 ----" << std::endl; print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
정렬 전 ---- 5 3 1 6 4 7 2 정렬 후 ---- 1 2 3 6 5 7 4
와 같이 나옵니다. 앞서 partial_sort 함수는 일부만 정렬하는 함수라고 하였습니다. partial_sort 는 인자를 아래와 같이 3 개를 기본으로 받습니다.
std::partial_sort(start, middle, end)
이 때 정렬을 [stard, end) 전체 원소들 중에서 [start, middle) 까지 원소들이 전체 원소들 중에서 제일 작은애들 순으로 정렬 시킵니다. 예를 들어서 위 경우
std::partial_sort(vec.begin(), vec.begin() + 3, vec.end());
위와 같이 vec.begin() 부터 vec.end() 까지 (즉 벡터 전체에서) 원소들 중에서, vec.begin() 부터 vec.begin() + 3 까지에 전체에서 가장 작은 애들만 순서대로 저장하고 나머지 위치는 상관 없다! 이런 식입니다. 따라서 위와 같이
5 3 1 6 4 7 2
에서 가장 작은 3개 원소인 1, 2, 3 만이 정렬되어서
1 2 3 6 5 7 4
앞에 나타나게 되고 나머지 원소들은 그냥 랜덤하게 남아있게 됩니다. 전체 원소의 개수가 N 개이고, 정렬하려는 부분의 크기가 M 이라면 partial_sort 의 복잡도는 $O(N \log M)$ 가 됩니다.
만약에 우리가 전체 배열을 정렬할 필요가 없을 경우, 예를 들어서 100 명의 학생 중에서 상위 10 명의 학생의 성적순을 보고 싶다, 이런 식이면 굳이 sort 로 전체를 정렬 할 필요 없이 partial_sort 로 10 개만 정렬 하는 것이 더 빠르게 됩니다.
마지막으로 stable_sort 에 대해 살펴보도록 하겠습니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } struct User { std::string name; int age; User(std::string name, int age) : name(name), age(age) {} bool operator<(const User& u) const { return age < u.age; } }; std::ostream& operator<<(std::ostream& o, const User& u) { o << u.name << " , " << u.age; return o; } int main() { std::vector<User> vec; for (int i = 0; i < 100; i++) { std::string name = ""; name.push_back('a' + i / 26); name.push_back('a' + i % 26); vec.push_back(User(name, static_cast<int>(rand() % 10))); } std::vector<User> vec2 = vec; std::cout << "정렬 전 ----" << std::endl; print(vec.begin(), vec.end()); std::sort(vec.begin(), vec.end()); std::cout << "정렬 후 ----" << std::endl; print(vec.begin(), vec.end()); std::cout << "stable_sort 의 경우 ---" << std::endl; std::stable_sort(vec2.begin(), vec2.end()); print(vec2.begin(), vec2.end()); }
성공적으로 컴파일 하였다면
와 같이 나옵니다.
앞서 stable_sort 는 원소가 삽입되어 있는 순서를 보존하는 정렬 방식이라고 하였습니다. stable_sort 가 확실히 어떻게 sort 와 다른지 보여주기 위해서 다음과 같은 클래스를 만들었습니다.
struct User { std::string name; int age; User(std::string name, int age) : name(name), age(age) {} bool operator<(const User& u) const { return age < u.age; } };
이 User 클래스는 name 과 age 를 멤버로 갖는데, 크기 비교는 이름과 관계없이 모두 age 로 하게 됩니다. 즉 age 가 같다면 크기가 같다고 볼 수 있습니다.
for (int i = 0; i < 100; i++) { std::string name = ""; name.push_back('a' + i / 26); name.push_back('a' + i % 26); vec.push_back(User(name, static_cast<int>(rand() % 10))); }
처음에 벡터에 원소들을 쭈르륵 삽입하는 부분인데, 이름은 aa, ab, ac, ... 순으로 하되 age 의 경우 0 부터 10 사이의 랜덤한 값을 부여하였습니다. 즉 name 의 경우 string 순서대로 되어있고, age 의 경우 랜덤한 순서로 되어 있습니다.
앞서 말했듯이 stable_sort 는 삽입되어 있던 원소들 간의 순서를 보존한다고 하였습니다. 따라서 같은 age 라면 반드시 삽입된 순서, 즉 name 순으로 나올 것입니다. (왜냐하면 애초에 name 순으로 넣었기 때문!)
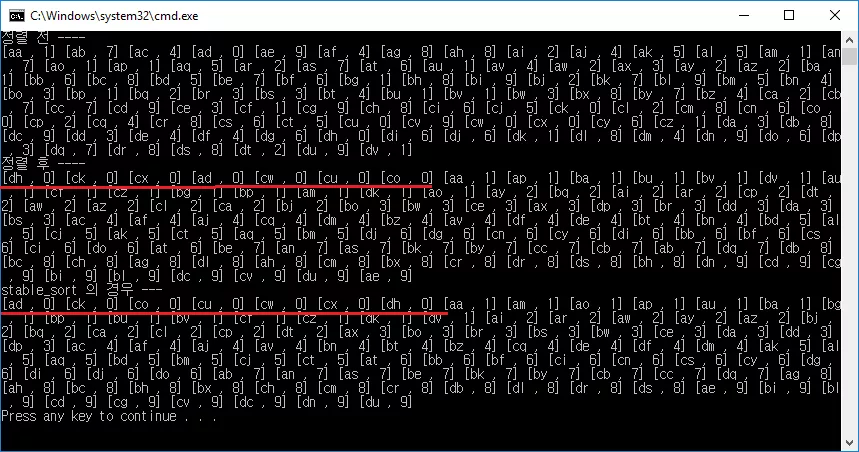
그 결과를 살펴보면 확연히 다름을 알 수 있습니다. 먼저 sort 의 경우
dh, ck, cx, ad, cw, cu, co
순으로 나와 있고 (age 가 0 일 때) stable_sort 의 경우 age 가 0 일 때
ad, ck, co, cu, cw, cx, dh
순으로 나오게 됩니다. 다시 말해 sort 함수의 경우 정렬 과정에서 원소들 간의 상대적 위치를 랜덤하게 바꿔버리지만 stable_sort 의 경우 그 순서를 처음에 넣었던 상태 그대로 유지함을 알 수 있습니다.
당연히도 이러한 제약 조건 때문에 stable_sort 는 그냥 sort 보다 좀 더 오래걸립니다. C++ 표준에 따르면 sort 함수는 최악의 경우에서도 O(n log n) 이 보장되지만 stable_sort 의 경우 최악의 경우에서 O(n (log n)^2) 으로 작동하게 됩니다. 조금 더 느린 편이지요.
원소 제거 (remove, remove_if)
다음으로 살펴볼 함수는 원소를 제거하는 함수 입니다. 사실 이미 대부분의 컨테이너에서는 원소를 제거하는 함수를 지원하고 있습니다. 예를 들어서,
std::vector<int> vec; // .... vec.erase(vec.begin() + 3);
을 하게 되면, vec[3] 에 해당하는 원소를 제거하게 됩니다.
그런데 사실 이 함수 하나로는 많은 작업들을 처리하기에 부족합니다. 예를 들어서 벡터에서 값이 3 인 원소를 제거하려면 어떻게 해야 할까요? 이전 강좌에서 다루었지만 아마 아래와 같이 할 수 있을 것입니다.
std::vector<int>::iterator itr = vec.begin(); for (; itr != vec.end(); ++itr) { if (*itr == 3) { vec.erase(itr); itr = vec.begin(); } }
이렇게 했던 이유는 바로 원소가 제거될 때 마다 기존에 제거하였던 반복자들이 초기화 되기 때문입니다. 따라서 해당 위치를 가리키는 반복자를 다시 가져와야 되지요. 물론 굳이 반복자를 쓰지 않고 그냥 일반 변수를 이용해서 배열을 다루듯이 처리할 수 도 있겠지만 '원소 접근은 반복자로 수행한다' 에 따른 약속에는 충실한 방법이 아닙니다.
그렇다면 어떻게 이를 해결할 수 있을까요?
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터에서 값이 3 인 원소 제거 ---" << std::endl; vec.erase(std::remove(vec.begin(), vec.end(), 3), vec.end()); print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
처음 vec 상태 ------ [5] [3] [1] [2] [3] [4] 벡터에서 값이 3 인 원소 제거 --- [5] [1] [2] [4]
와 같이 나옵니다.
위 코드가 어떻게 작동하는지 설명하기에 앞서 erase 함수를 살펴보도록 합시다. 벡터의 erase 함수는 2 가지 형태가 있는데, 하나는 우리가 잘 알고 있는
Iterator erase(Iterator pos);
와 같은 형태가 있고, 다른 하나는
Iterator erase(Iterator first, Iterator last);
와 같은 형태가 있습니다. 전자의 경우 그냥 pos 가 가리키는 원소를 벡터에서 지우지만 후자의 경우 first 부터 last 사이에 있는 모든 원소들을 지우는 형태 입니다. 물론 이 두 함수 모두 우리의 목표인 '값이 3 인 원소 제거' 를 수행하는데 부족함이 있습니다. 물론 후자의 함수를 사용하면 좋겠지만, 값이 3 인 원소들이 벡터에서 연속적으로 존재하지 않기 때문이지요.
하지만 어떤 편리한 함수가 있어서 값이 3 인 원소들을 벡터에서 연속적으로 존재할 수 있게 해주면 어떨까요?
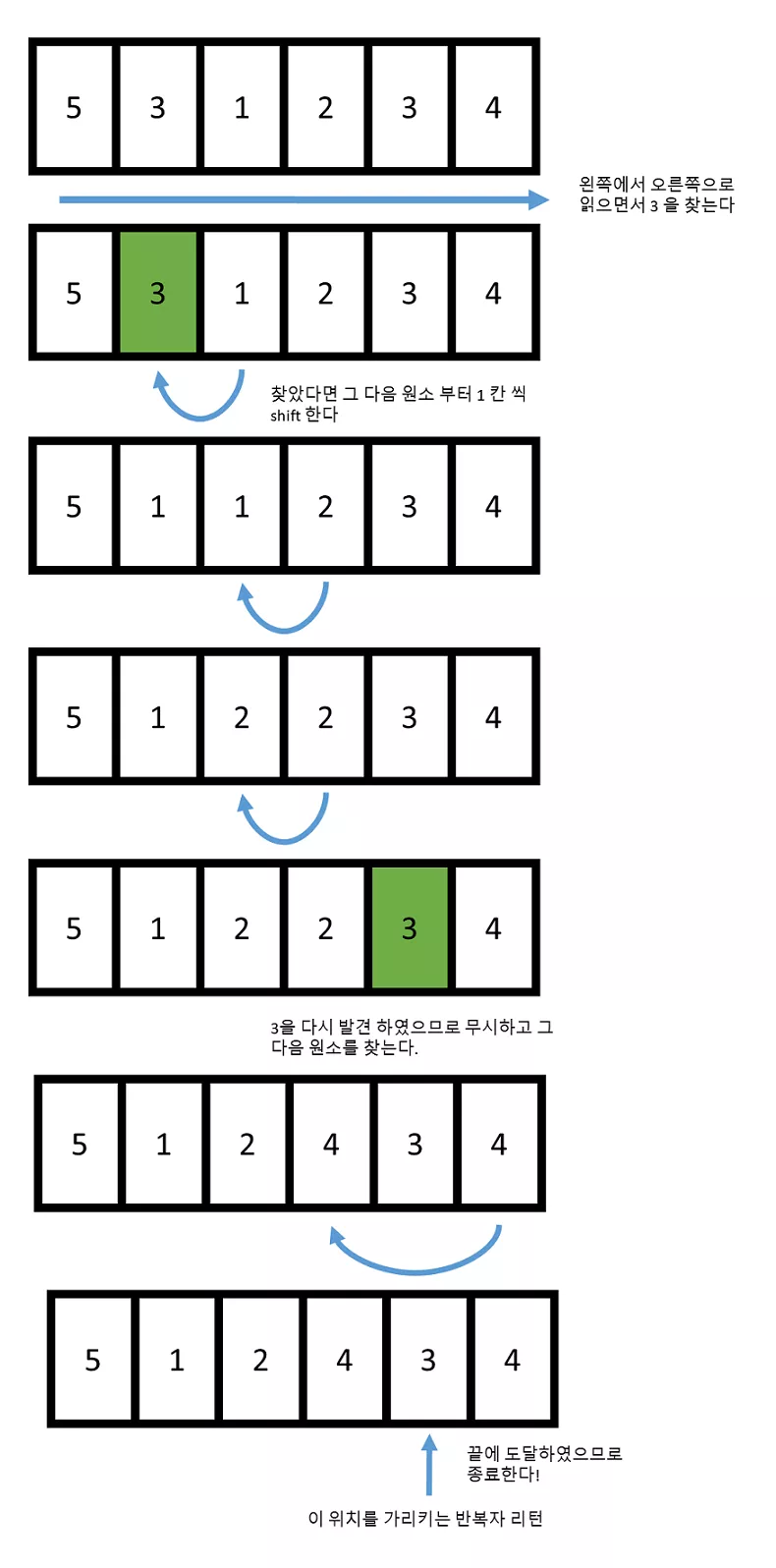
위와 같이, 만일 값이 3 인 원소를 만나면 그 뒤에 있는 원소들로 쭈르륵 쉬프트 해주게 됩니다. 따라서, 자연스럽게 알고리즘이 끝나게 되면은 해당하는 위치에서 전 까지 3 이 제외된 원소들로 쭈르륵 채워지게 되겠지요.
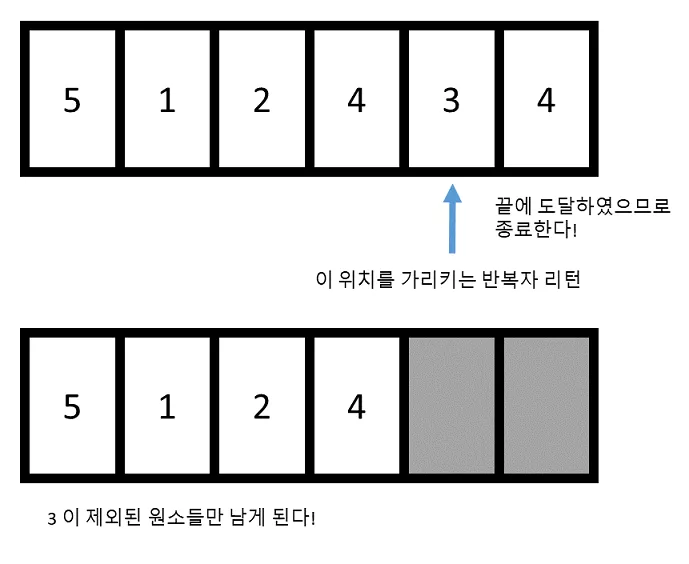
다시말해, 반복이 끝나는 위치 부터 벡터 맨 뒤 까지 제거해버리면 3 이 싹 제거된 벡터만 남게 되지요. remove 함수는 원소의 이동만을 수행하지 실제로 원소를 삭제하는 연산을 수행하지는 않습니다. 따라서 벡터에서 실제로 원소를 지우기 위해서는 반드시 erase 함수를 호출하여 실제로 원소를 지워줘야만 합니다.
vec.erase(remove(vec.begin(), vec.end(), 3), vec.end());
따라서 위 처럼 remove 함수를 이용해서 값이 3 인 원소들을 뒤로 보내버리고, 그 원소들을 벡터에서 삭제해버리게 됩니다.
참고로 말하자면 remove 함수의 경우 반복자의 타입이 ForwardIterator 입니다. 즉, 벡터 뿐만이 아니라, 리스트, 혹은 셋이나 맵에서도 모두 사용할 수 있습니다!
그렇다면 이번에는 값이 딱 얼마로 정해진 것이 아니라 특정한 조건을 만족하는 원소들을 제거하려면 어떻게 해야 할까요? 당연히도 이 원소가 그 조건을 만족하는지 아닌지를 판단할 함수를 전달해야 됩니다. 이를 위해선 remove_if 함수를 사용해야 합니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } struct is_odd { bool operator()(const int& i) { return i % 2 == 1; } }; int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터에서 홀수 인 원소 제거 ---" << std::endl; vec.erase(std::remove_if(vec.begin(), vec.end(), is_odd()), vec.end()); print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
처음 vec 상태 ------ [5] [3] [1] [2] [3] [4] 벡터에서 홀수 인 원소 제거 --- [2] [4]
와 같이 나옵니다.
vec.erase(remove_if(vec.begin(), vec.end(), is_odd()), vec.end());
remove_if 함수는 세번째 인자로 조건을 설명할 함수 객체를 전달받습니다.
struct is_odd { bool operator()(const int& i) { return i % 2 == 1; } };
위와 같이 is_odd 구조체에 operator() 를 만들어서 함수 객체를 전달하시면 됩니다. 당연히도, 함수 객체로 실제 함수를 전달할 수 도 있습니다. 이 경우
template <typename Iter, typename Pred> remove_if(Iter first, Iter last, Pred pred)
에서 Pred 가 함수 포인터 타입이 되겠지요.
bool odd(const int& i) { return i % 2 == 1; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터에서 홀수 인 원소 제거 ---" << std::endl; vec.erase(std::remove_if(vec.begin(), vec.end(), odd), vec.end()); print(vec.begin(), vec.end()); }
위와 같이 실제 함수를 전달한다면 앞서 만들었던 함수 객체와 정확히 동일하게 동작합니다.
remove_if 에 조건 추가하기
우리의 remove_if 함수는 함수 객체가 인자를 딱 1 개 만 받는다고 가정합니다. 따라서 호출되는 operator() 을 통해선 원소에 대한 정보 말고는 추가적인 정보를 전달하기는 어렵습니다.
하지만 예를 들어서 홀수인 원소들을 삭제하되 처음 2개만 삭제한다고 해봅시다. 함수 객체의 경우 사실 클래스의 객체이기 때문에 멤버 변수를 생각할 수 있습니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } struct is_odd { int num_delete; is_odd() : num_delete(0) {} bool operator()(const int& i) { if (num_delete >= 2) return false; if (i % 2 == 1) { num_delete++; return true; } return false; } }; int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터에서 홀수인 원소 앞의 2개 제거 ---" << std::endl; vec.erase(std::remove_if(vec.begin(), vec.end(), is_odd()), vec.end()); print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
처음 vec 상태 ------ [5] [3] [1] [2] [3] [4] 벡터에서 홀수인 원소 앞의 2개 제거 --- [2] [3] [4]
와 같이 나옵니다.
struct is_odd { int num_delete; is_odd() : num_delete(0) {} bool operator()(const int& i) { if (num_delete >= 2) return false; if (i % 2 == 1) { num_delete++; return true; } return false; } };
예상과는 사뭇 다른 결과가 나왔습니다. 홀수 원소 2 개가 아니라 3 개가 삭제됬네요. 분명히 우리는 2개 이상 되면 false 를 리턴하라고 명시했는데도 말이지요.
사실 C++ 표준에 따르면 remove_if 에 전달되는 함수 객체의 경우 이전의 호출에 의해 내부 상태가 달라지면 안됩니다. 다시 말해, 위 처럼 함수 객체 안에 인스턴스 변수 (num_delete) 를 넣는 것은 원칙상 안된다는 것이지요.
그 이유는 remove_if 를 실제로 구현 했을 때, 해당 함수 객체가 여러번 복사 될 수 있기 때문입니다. 물론, 이는 어떻게 구현하냐에 따라서 달라집니다. 예를 들어 아래 버전을 살펴볼까요.
template <class ForwardIterator, class UnaryPredicate> ForwardIterator remove_if(ForwardIterator first, ForwardIterator last, UnaryPredicate pred) { ForwardIterator result = first; while (first != last) { if (!pred(*first)) { // <-- 함수 객체 pred 를 실행하는 부분 *result = std::move(*first); ++result; } ++first; } return result; }
위 버전에 경우 인자로 전달된 함수 객체 pred 는 복사되지 않고 계속 호출됩니다. 따라서 사실 우리의 원래 코드가 위 remove_if 를 바탕으로 실행됬더라면 2 개만 정확히 지워질 수 있습니다.
하지만 문제는 C++ 표준은 remove_if 함수를 어떤 방식으로 구현하라고 정해 놓지 않습니다. 어떤 라이브러리들의 경우 아래와 같은 방식으로 구현되었습니다 (사실 대부분의 라이브러리들이 아래와 비슷합니다.)
template <class ForwardIt, class UnaryPredicate> ForwardIt remove_if(ForwardIt first, ForwardIt last, UnaryPredicate pred) { first = std::find_if(first, last, pred); // <- pred 한 번 복사됨 if (first != last) // 아래 for 문은 first + 1 부터 시작한다고 봐도 된다 (++i != last) for (ForwardIt i = first; ++i != last;) if (!pred(*i)) // <-- pred 호출 하는 부분 *first++ = std::move(*i); return first; }
참고로 find_if 함수의 경우 인자로 전달된 조건 pred 가 참인 첫 번째 원소를 리턴합니다. 그런데 문제는 find_if 가 함수 객체 pred 의 레퍼런스를 받는 것이 아니라, 복사 생성된 버전을 받는다는 점입니다. 따라서, find_if 호출 후에 아래 for 문에서 이미 한 개 원소를 지웠다는 정보가 소멸되게 됩니다. 후에 호출되는 pred 들은 이미 num_delete 가 1 인지 모른 채 0 부터 다시 시작하게 되죠.
다시 한 번 말하자면, 함수 객체에는 절대로 특정 상태를 저장해서 이에 따라 결과가 달라지는 루틴을 짜면 안됩니다. 위 처럼 이해하기 힘든 오류가 발생할 수 도 있습니다.
그렇다면 위 문제를 어떻게 하면 해결할 수 있을 까요? 한 가지 방법은 num_delete 를 객체 내부 변수가 아니라 외부 변수로 빼는 방법입니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } struct is_odd { int* num_delete; is_odd(int* num_delete) : num_delete(num_delete) {} bool operator()(const int& i) { if (*num_delete >= 2) return false; if (i % 2 == 1) { (*num_delete)++; return true; } return false; } }; int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터에서 홀수인 원소 앞의 2개 제거 ---" << std::endl; int num_delete = 0; vec.erase(std::remove_if(vec.begin(), vec.end(), is_odd(&num_delete)), vec.end()); print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
처음 vec 상태 ------ [5] [3] [1] [2] [3] [4] 벡터에서 홀수인 원소 앞의 2개 제거 --- [1] [2] [3] [4]
와 같이 제대로 나옵니다. 위 경우, num_delete 에 관한 정보를 아예 함수 객체 밖으로 빼서 보관해버렸습니다. 물론 함수 객체에 내부 상태인 num_delete 의 주소값은 변하지 않으므로 문제될 것이 없습니다.
그런데 한 가지 안좋은 점은 이렇게 STL 을 사용할 때 마다 외부에 클래스나 함수를 하나 씩 만들어줘야 된다는 점입니다. 물론 프로젝트의 크기가 작다면 크게 문제가 되지는 않겠지만 프로젝트의 크기가 커진다면, 만약 다른 사람이 코드를 읽을 때 '이 클래스는 뭐하는 거지?' 혹은 '이 함수는 뭐하는 거지?' 와 같은 궁금증이 생길 수 도 있고 심지어 잘못 사용할 수 도 있습니다.
따라서 가장 이상적인 방법은 STL 알고리즘을 사용할 때 그 안에 직접 써놓는 것입니다. 마치
vec.erase(std::remove_if(vec.begin(), vec.end(), bool is_odd(int i) { return i % 2 == 1; }), vec.end());
뭐 이런 식으로 말이지요. 문제는 위 문법이 C++ 에서 허용되지 않다는 점입니다. 하지만 놀랍게도 C++ 11 부터 위 문제를 해결할 방법이 나타났습니다.
람다 함수(lambda function)
람다 함수는 C++ 에서는 C++ 11 에서 처음으로 도입되었습니다. 람다 함수를 통해 쉽게 이름이 없는 함수 객체를 만들수 없게 되었습니다. 그렇습니다.익명의 함수 객체 말입니다.
람다 함수를 사용한 예제 부터 먼저 살펴보겠습니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터에서 홀수인 원소 제거 ---" << std::endl; vec.erase(std::remove_if(vec.begin(), vec.end(), [](int i) -> bool { return i % 2 == 1; }), vec.end()); print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
처음 vec 상태 ------ [5] [3] [1] [2] [3] [4] 벡터에서 홀수인 원소 제거 --- [2] [4]
와 같이 나옵니다.
람다 함수를 정의한 부분부터 살펴보도록 합시다.
[](int i) -> bool { return i % 2 == 1; }
람다 함수는 위와 같은 꼴로 정의됩니다. 일반적인 꼴을 살펴보자면
[capture list] (받는 인자) -> 리턴 타입 { 함수 본체 }
와 같은 형태 입니다. capture_list 가 뭔지는 아래에서 설명하도록 하고, 위 함수 꼴을 살펴보자면 인자로 int i 를 받고, bool 을 리턴하는 람다 함수를 정의한 것입니다. 리턴 타입을 생략한다면 컴파일러가 알아서 함수 본체에서 return 문을 보고 리턴 타입을 추측해줍니다. (만약에 return 경로가 여러군데여서 추측할 수 없다면 컴파일 오류가 발생하지요)
리턴 타입을 생략할 경우
[capture list] ( 받는 인자) {함수 본체}
이런 식으로 더 간단히 쓸 수 있습니다. 위 예제의 경우
[](int i) { return i % 2 == 1; }
로 쓴다면 알아서 "아 bool 타입을 리턴하는 함수구나" 라고 컴파일러가 만들어줍니다.
앞서 람다 함수가 이름이 없는 함수라 했는데 실제로 위를 보면 함수에 이름이 붙어 있지 않습니다! 즉 임시적으로 함수를 생성한 것이지요. 만약에 이 함수를 사용하고 싶다면
[](int i) { return i % 2 == 1; }(3); // true
와 같이 그냥 바로 호출할 수 도 있고
auto func = [](int i) { return i % 2 == 1; }; func(4); // false;
람다 함수로 func 이라는 함수 객체를 생성한 후에 호출할 수 도 있지요.
하지만 람다 함수도 말 그대로 함수 이기 때문에 자기 자신만의 스코프를 가집니다. 따라서 일반적인 상황이라면 함수 외부에서 정의된 변수들을 사용할 수 없겠지요. 예를 들어서 최대 2 개 원소만 지우고 싶은 경우
std::cout << "벡터에서 홀수인 원소 최대 2 개 제거 ---" << std::endl; int num_erased = 0; vec.erase(std::remove_if(vec.begin(), vec.end(), [](int i) { if (num_erased >= 2) return false; else if (i % 2 == 1) { num_erased++; return true; } return false; }), vec.end()); print(vec.begin(), vec.end());
위와 같이 람다 함수 외부에 몇 개를 지웠는지 변수를 정의한 뒤에 사용해야만 하는데 (함수 안에 정의하면 함수 호출될 때 마다 새로 생성되니까요!) 문제는 그 변수에 접근할 수 없다는 점입니다. 하지만 놀랍게도 람다 함수의 경우 그 변수에 접근할 수 있습니다. 바로 캡쳐 목록(capture list)을 사용하는 것입니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터에서 홀수인 원소 ---" << std::endl; int num_erased = 0; vec.erase(std::remove_if(vec.begin(), vec.end(), [&num_erased](int i) { if (num_erased >= 2) return false; else if (i % 2 == 1) { num_erased++; return true; } return false; }), vec.end()); print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
처음 vec 상태 ------ [5] [3] [1] [2] [3] [4] 벡터에서 홀수인 원소 --- [1] [2] [3] [4]
와 같이 잘 됨을 알 수 있습니다.
[&num_erased](int i) { if (num_erased >= 2) return false; else if (i % 2 == 1) { num_erased++; return true; } return false; })
위와 같이 캡쳐 목록에는 어떤 변수를 캡쳐할 지 써주면 됩니다. 위 경우 num_erased 를 캡쳐하였습니다. 즉 람다 함수 내에서 num_erased 를 마치 같은 스코프 안에 있는 것 처럼 사용할 수 있게 됩니다.
이 때 num_erased 앞에 & 가 붙어있는데 이는 실제 num_erased 의 레퍼런스를 캡쳐한다는 의미입니다. 즉 함수 내부에서 num_erased 의 값을 바꿀 수 있게 되지요. 만약에 아래처럼
[num_erased](int i){ if (num_erased >= 2) return false; else if (i % 2 == 1) { num_erased++; return true; } return false; })
& 를 앞에 붙이지 않는다면 num_erased 의 복사본을 얻게 되는데, 그 복사본의 형태는 const 입니다. 따라서 위 처럼 함수 내부에서 num_erased 의 값을 바꿀 수 없게 되지요. 그렇다면 클래스의 멤버 함수 안에서 람다를 사용할 때 멤버 변수들을 참조하려면 어떻게 해야 할까요?
class SomeClass { std::vector<int> vec; int num_erased; public: SomeClass() { vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); num_erased = 1; vec.erase(std::remove_if(vec.begin(), vec.end(), [&num_erased](int i) { if (num_erased >= 2) return false; else if (i % 2 == 1) { num_erased++; return true; } return false; }), vec.end()); } };
예를 들어 위와 같은 예제를 생각해봅시다. 쉽게 생각해보면 그냥 똑같이 num_erased 를 & 로 캡쳐해서 람다 함수 안에서 사용할 수 있을 것 같지만 실제로는 컴파일 되지 않습니다. 왜냐하면 num_erased 가 일반 변수가 아니라 객체에 종속되어 있는 멤버 변수 이기 때문이지요. 즉 람다 함수는 num_erased 를 캡쳐해! 라고 하면 이 num_erased 가 이 객체의 멤버 변수가 아니라 그냥 일반 변수라고 생각하게 됩니다.
이를 해결하기 위해선 직접 멤버 변수를 전달하기 보다는 this 를 전달해주면 됩니다.
num_erased = 0; vec.erase(std::remove_if(vec.begin(), vec.end(), [this](int i) { if (this->num_erased >= 2) return false; else if (i % 2 == 1) { this->num_erased++; return true; } return false; }), vec.end());
위와 같이 this 를 복사본으로 전달해서 (참고로 this 는 레퍼런스로 전달할 수 없습니다) 함수 안에서 this 를 이용해서 멤버 변수들을 참조해서 사용하면 됩니다.
위에 설명한 경우 말고도 캡쳐 리스트의 사용 방법은 꽤나 많은데 아래 간단히 정리해보도록 하겠습니다.
[]: 아무것도 캡쳐 안함[&a, b]:a는 레퍼런스로 캡쳐하고b는 (변경 불가능한) 복사본으로 캡쳐[&]: 외부의 모든 변수들을 레퍼런스로 캡쳐[=]: 외부의 모든 변수들을 복사본으로 캡쳐
와 같이 되겠습니다.
원소 수정하기 (transform)
다음으로 살펴볼 함수는 원소들을 수정하는 함수들 입니다. 많은 경우 컨테이너 전체 혹은 일부를 순회하면서 값들을 수정하는 작업을 많이 할 것입니다. 예를 들어서 벡터의 모든 원소에 1 씩 더한다와 같은 작업들을 말이지요. 이러한 작업을 도와주는 함수는 바로 transform 함수 입니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); std::cout << "처음 vec 상태 ------" << std::endl; print(vec.begin(), vec.end()); std::cout << "벡터 전체에 1 을 더한다" << std::endl; std::transform(vec.begin(), vec.end(), vec.begin(), [](int i) { return i + 1; }); print(vec.begin(), vec.end()); }
성공적으로 컴파일 하였다면
실행 결과
처음 vec 상태 ------ [5] [3] [1] [2] [3] [4] 벡터 전체에 1 을 더한다 [6] [4] [2] [3] [4] [5]
와 같이 나옵니다.
transform 함수는 다음과 같은 꼴로 생겼습니다.
transform (시작 반복자, 끝 반복자, 결과를 저장할 컨테이너의 시작 반복자, Pred)
우리가 사용한 예의 경우
transform(vec.begin(), vec.end(), vec.begin(), [](int i) { return i + 1; });
로 하였으므로 vec 의 시작(begin) 부터 끝(end) 까지 각 원소에 [] (int i) {return i + 1} 함수를 적용시킨 결과를 vec.begin() 부터 저장하게 됩니다. 즉 결과적으로 각 원소에 1 을 더한 결과로 덮어 씌우게 되는 것이지요. 상당히 간단합니다. 한 가지 주의할 점은 값을 저장하는 컨테이너의 크기가 원래의 컨테이너보다 최소한 같거나 커야 된다는 점입니다. 예를 들어서 단순하게
std::transform(vec.begin(), vec.end(), vec.begin() + 1, [](int i) { return i + 1; });
이렇게 썻다고 해봅시다. transform 함수는 vec 의 처음 부터 끝까지 쭈르륵 순회하지만 저장하는 쪽의 반복자는 vec 의 두 번째 원소 부터 저장하기 때문에 결과적으로 마지막에 한 칸이 모잘라서
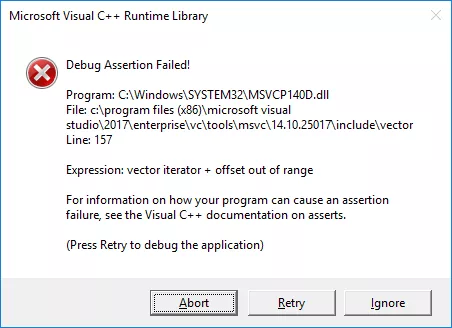
위와 같은 오류를 발생하게 됩니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); // vec2 에는 6 개의 0 으로 초기화 한다. std::vector<int> vec2(6, 0); std::cout << "처음 vec 과 vec2 상태 ------" << std::endl; print(vec.begin(), vec.end()); print(vec2.begin(), vec2.end()); std::cout << "vec 전체에 1 을 더한 것을 vec2 에 저장 -- " << std::endl; std::transform(vec.begin(), vec.end(), vec2.begin(), [](int i) { return i + 1; }); print(vec.begin(), vec.end()); print(vec2.begin(), vec2.end()); }
성공적으로 컴파일 하였으면
실행 결과
처음 vec 과 vec2 상태 ------ [5] [3] [1] [2] [3] [4] [0] [0] [0] [0] [0] [0] vec 전체에 1 을 더한 것을 vec2 에 저장 -- [5] [3] [1] [2] [3] [4] [6] [4] [2] [3] [4] [5]
와 같이 나옵니다.
std::transform(vec.begin(), vec.end(), vec2.begin(), [](int i) { return i + 1; });
위와 같이 vec 의 처음 부터 끝 까지 읽으면서 1 씩 더한 결과를 vec2 에 저장하게 됩니다. 간단하지요! 물론 저 transform 함수 하나 덕분에 귀찮에 for 문을 쓸 필요도 없어질 뿐더러, 내가 이 코드에서 무슨 일을 하는지 더 간단 명료하게 나타낼 수 도 있습니다.
원소를 탐색하는 함수(find, `find_if, any_of, all_of` 등등)
마지막으로 살펴볼 함수들은 원소들을 탐색하는 계열의 함수들 입니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); auto result = std::find(vec.begin(), vec.end(), 3); std::cout << "3 은 " << std::distance(vec.begin(), result) + 1 << " 번째 원소" << std::endl; }
성공적으로 컴파일 하였으면
실행 결과
3 은 2 번째 원소
와 같이 나옵니다.
find 함수는 단순히
template <class InputIt, class T> InputIt find(InputIt first, InputIt last, const T& value)
와 같이 생겼는데, first 부터 last 까지 쭈르륵 순회하면서 value 와 같은 원소가 있는지 확인하고 있으면 이를 가리키는 반복자를 리턴합니다. 위 경우
auto result = std::find(vec.begin(), vec.end(), 3);
vec 에서 값이 3 과 같은 원소를 찾아서 리턴하게 되지요. 반복자에 따라서 forward_iterator 면 앞에서 부터 찾고, reverse_iterator 이면 뒤에서 부터 거꾸로 찾게 됩니다. 물론 컨테이너에 중복되는 값이 있더라도 가장 먼저 찾은 것을 리턴합니다. 만약에 위 vec 에서 모든 3 을 찾고 싶다면 아래와 같이 하면 됩니다.
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); auto current = vec.begin(); while (true) { current = std::find(current, vec.end(), 3); if (current == vec.end()) break; std::cout << "3 은 " << std::distance(vec.begin(), current) + 1 << " 번째 원소" << std::endl; current++; } }
성공적으로 컴파일 하였다면
실행 결과
3 은 2 번째 원소 3 은 5 번째 원소
위와 같이 나옵니다.
current = find(current, vec.end(), 3);
위 처럼 마지막으로 찾은 위치 바로 다음 부터 계속 순차적으로 탐색해 나간다면 컨테이너에서 값이 3 인 원소들을 모두 찾을 수 있게 됩니다.
다만 find 계열의 함수들을 사용할 때 한 가지 주의해야 할 점은, 만약에 컨테이너에서 기본적으로 find 함수를 지원한다면 이를 사용하는 것이 훨씬 빠릅니다. 왜냐하면 알고리즘 라이브러리에서의 find 함수는 그 컨테이너가 어떠한 구조를 가지고 있는지에 대한 정보가 하나도 없기 때문입니다.
예를 들어 set 의 경우, set 에서 사용하는 find 함수의 경우 $O(\log n)$ 으로 수행될 수 있는데 그 이유는 셋 내부에서 원소들이 정렬되어 있기 때문입니다. 또 unordered_set 의 경우 find 함수가 $O(1)$ 로 수행될 수 있는데 그 이유는 unordered_set 내부에서 자체적으로 해시 테이블을 이용해서 원소들을 빠르게 탐색해 나갈 수 있기 때문입니다.
하지만 그냥 알고리즘 라이브러리의 find 함수의 경우 이러한 추가 정보가 있는 것을 하나도 모른채 우직하게 처음 부터 하나 씩 확인해 나가므로 평범한 $O(n)$ 으로 처리됩니다. 따라서 알고리즘 라이브러리의 find 함수를 사용할 경우 벡터와 같이 기본적으로 find 함수를 지원하지 않는 컨테이너에 사용하시기 바랍니다!
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } int main() { std::vector<int> vec; vec.push_back(5); vec.push_back(3); vec.push_back(1); vec.push_back(2); vec.push_back(3); vec.push_back(4); auto current = vec.begin(); while (true) { current = std::find_if(current, vec.end(), [](int i) { return i % 3 == 2; }); if (current == vec.end()) break; std::cout << "3 으로 나눈 나머지가 2 인 원소는 : " << *current << " 이다 " << std::endl; current++; } }
성공적으로 컴파일 하였다면
실행 결과
3 으로 나눈 나머지가 2 인 원소는 : 5 이다 3 으로 나눈 나머지가 2 인 원소는 : 2 이다
와 같이 나옵니다.
current = std::find_if(current, vec.end(), [](int i) { return i % 3 == 2; });
find 함수가 단순한 값을 받았다면 find_if 함수의 경우 함수 객체를 인자로 받아서 그 결과가 참인 원소들을 찾게 됩니다. 위 경우 3 으로 나눈 나머지가 2 인 원소들을 컨테이너에서 탐색하였습니다. 람다 함수로 사용하니 엄청 간결하지요?
#include <algorithm> #include <functional> #include <iostream> #include <string> #include <vector> template <typename Iter> void print(Iter begin, Iter end) { while (begin != end) { std::cout << "[" << *begin << "] "; begin++; } std::cout << std::endl; } struct User { std::string name; int level; User(std::string name, int level) : name(name), level(level) {} bool operator==(const User& user) const { if (name == user.name && level == user.level) return true; return false; } }; class Party { std::vector<User> users; public: bool add_user(std::string name, int level) { User new_user(name, level); if (std::find(users.begin(), users.end(), new_user) != users.end()) { return false; } users.push_back(new_user); return true; } // 파티원 모두가 15 레벨 이상이여야지 던전 입장 가능 bool can_join_dungeon() { return std::all_of(users.begin(), users.end(), [](User& user) { return user.level >= 15; }); } // 파티원 중 한명 이라도 19렙 이상이면 특별 아이템 사용 가능 bool can_use_special_item() { return std::any_of(users.begin(), users.end(), [](User& user) { return user.level >= 19; }); } }; int main() { Party party; party.add_user("철수", 15); party.add_user("영희", 18); party.add_user("민수", 12); party.add_user("수빈", 19); std::cout << std::boolalpha; std::cout << "던전 입장 가능 ? " << party.can_join_dungeon() << std::endl; std::cout << "특별 아이템 사용 가능 ? " << party.can_use_special_item() << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
던전 입장 가능 ? false 특별 아이템 사용 가능 ? true
와 같이 나옵니다.
마지막으로 살펴볼 함수들은 any_of 와 all_of 입니다. any_of 는 인자로 받은 범위안의 모든 원소들 중에서 조건을 하나라도 충족하는 것이 있다면 true 를 리턴하고 all_of 의 경우 모든 원소들이 전부 조건을 충족해야 true 를 리턴합니다. 즉 any_of 는 OR 연산과 비슷하고 all_of 는 AND 연산과 비슷하다고 볼 수 있지요.
bool add_user(std::string name, int level) { User new_user(name, level); if (std::find(users.begin(), users.end(), new_user) != users.end()) { return false; } users.push_back(new_user); return true; }
먼저 간단히 유저들의 정보를 담고 있는 User 구조체를 정의하였고, 그 User 들이 파티를 이룰 때 만들어지는 Party 클래스를 정의하였습니다. 그리고 위 add_user 함수를 사용하면 파티원을 추가할 수 있지요. 물론 중복되는 파티원이 없도록 벡터에 원소를 추가하기 전에 확인합니다.
// 파티원 모두가 15 레벨 이상이여야지 던전 입장 가능 bool can_join_dungeon() { return std::all_of(users.begin(), users.end(), [](User& user) { return user.level >= 15; }); }
따라서 이 파티가 어떤 던전에 참가하고 싶은 경우 모든 파티원의 레벨이 15 이상 이어야 하므로 위와 같이 all_of 함수를 사용해서 모든 원소들이 조건에 만족하는지 확인할 수 있습니다. 위 경우 민수가 12 레벨이여서 false 가 리턴되겠지요.
// 파티원 중 한명 이라도 19렙 이상이면 특별 아이템 사용 가능 bool can_use_special_item() { return std::any_of(users.begin(), users.end(), [](User& user) { return user.level >= 19; }); }
비슷하게도 한 명만 조건을 만족해도 되는 경우 위와 같이 any_of 함수를 사용하면 간단히 처리할 수 있습니다.
자 그러면 이번 강좌는 여기서 마치도록 하겠습니다. 사실 알고리즘 라이브러리를 살펴보면 이것 보다도 훨씬 많은 수의 여러가지 유용한 함수들이 정의되어 있습니다. 하지만 이 모든 함수들을 강좌에서 다루기에는 조금 무리가 있고, 이 정도 함수들만 알아놓아도 매우 편리하게 사용하실 수 있을 것이라 생각합니다!

댓글을 불러오는 중입니다..