모두의 코드
씹어먹는 C++ - <9 - 1. 코드를 찍어내는 틀 - C++ 템플릿(template)>
이번 강좌에서는
C++ 템플릿 (template) 도입
클래스 템플릿과 함수 템플릿
템플릿 인스턴스화와 템플릿 특수화
함수 객체 (Functor)
타입이 아닌 템플릿 인자
디폴트 템플릿 인지
에 대해서 배웁니다.

안녕하세요 여러분! 지난번 강좌 생각해보기는 잘 해결 하셨나요? 뭐 해결 하지 못하고 넘어왔더라도 괜찮습니다. 이번 강좌에서는 여태까지 배워 왔던 것과 전혀 다른 새로운 세계를 탐험해 볼 것입니다.
지난번 강좌에서 벡터와 스택 자료형을 만드셨던 것을 기억 하시나요? 벡터(vector) 는 쉽게 생각하면 가변 길이 배열로 사용자가 배열 처럼 사용하는데 크기를 마음대로 줄이고 늘일 수 있는 편리한 자료형입니다. 스택(stack)의 경우 나중에 들어간 것이 먼저 나온다(LIFO - last in first out) 형태의 자료형으로 pop 과 push 를 통해서 여러가지 작업들을 처리할 수 있습니다.
하지만 한 가지 문제는 우리가 담으려고 하는 데이터 타입이 바뀔 때 마다 다른 벡터를 만들어주어야 한다는 점이 있습니다. 예를 들어서 아래의 Vector 클래스를 살펴봅시다.
class Vector { std::string* data; int capacity; int length; public: // 생성자 Vector(int n = 1) : data(new std::string[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(std::string s) { if (capacity <= length) { std::string* temp = new std::string[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. std::string operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } ~Vector() { if (data) { delete[] data; } } };
위 Vector 클래스의 경우 string 데이터 밖에 저장할 수 없습니다. 만일 사용자가 int 를 원한다면 어떨까요? 혹은 char 데이터를 담고 싶다면 어떻게 할까요? 물론, 각각의 경우에서 코드만 살짝 살짝 바꿔주면 될 것입니다. 예를 들어서 char 을 담는 Vector 의 경우
class Vector { char* data; int capacity; int length; public: // 생성자 Vector(int n = 1) : data(new char[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(char s) { if (capacity <= length) { char* temp = new char[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. char operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } ~Vector() { if (data) { delete[] data; } } };
위와 같이 string 부분만 살짝 char 로 바꿔주면 됩니다. 하지만 이는 큰 낭비가 아닐 수 없습니다. 위 char 을 보관하는 vector 와 string 을 보관하는 vector 의 코드는 단순히 string 부분이 char 로 바뀐 차이 밖에 없습니다. 나머지 부분은 정확히 일치합니다.
쉽게 말해서 우리가 T 라는 타입의 객체들을 보관하는 vector 를 만들고 싶을 경우
class Vector { T* data; int capacity; int length; public: // 생성자 Vector(int n = 1) : data(new T[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(T s) { if (capacity <= length) { T* temp = new T[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. T operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } ~Vector() { if (data) { delete[] data; } } };
만약에 우리가 int 를 담는 vector 가 필요할 경우 T 를 int 로 바뀌면 되고, string 을 담는 것이 필요하다면 T 가 string 으로 바뀌면 됩니다. 쉽게 말해 컴파일러가 T 부분에 우리가 원하는 타입으로 채워서 코드를 생성해주면 엄청 편할 것입니다.
마치 어떠한 틀에 타입을 집어넣으면 원하는 코드가 딱딱 튀어 나오는 틀 같이 말이죠.
C++ 템플릿(template)
놀랍게도, 우리가 원하는 작업을 C++ 에서는 template 이라는 이름으로 지원하고 있습니다. 영어 단어 template 의 뜻을 찾아보자면, 형판 이라고 나옵니다. 쉽게 말해 어떠한 물건을 찍어내는 틀 이라고 생각하면 됩니다.
C++ 에서도 정확히 같은 의미로 사용되고 있습니다. 사용자 (프로그래머)가 원하는 타입을 넣어주면 딱딱 알아서 코드를 찍어내는 틀 이라고 생각하면 됩니다 C++ 에서도 정확히 같은 의미로 사용되고 있습니다. 사용자 (프로그래머)가 원하는 타입을 넣어주면 딱딱 알아서 코드를 찍어내는 틀 이라고 생각하면 됩니다.
// 템플릿 첫 활용 #include <iostream> #include <string> template <typename T> class Vector { T* data; int capacity; int length; public: // 생성자 Vector(int n = 1) : data(new T[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(T s) { if (capacity <= length) { T* temp = new T[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. T operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } ~Vector() { if (data) { delete[] data; } } }; int main() { // int 를 보관하는 벡터를 만든다. Vector<int> int_vec; int_vec.push_back(3); int_vec.push_back(2); std::cout << "-------- int vector ----------" << std::endl; std::cout << "첫번째 원소 : " << int_vec[0] << std::endl; std::cout << "두번째 원소 : " << int_vec[1] << std::endl; Vector<std::string> str_vec; str_vec.push_back("hello"); str_vec.push_back("world"); std::cout << "-------- std::string vector -------" << std::endl; std::cout << "첫번째 원소 : " << str_vec[0] << std::endl; std::cout << "두번째 원소 : " << str_vec[1] << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
-------- int vector ---------- 첫번째 원소 : 3 두번째 원소 : 2 -------- std::string vector ------- 첫번째 원소 : hello 두번째 원소 : world
와 같이 나옵니다.
일단 클래스 상단에 템플릿이 정의된 부분을 살펴봅시다.
template <typename T> class Vector { T* data; int capacity; // ...
맨 위에
template <typename T>
는아래에 정의되는 클래스에 대해 템플릿을 정의하고, 템플릿 인자로 T 를 받게 되며, T 는 반드시 어떠한 타입의 이름임을 명시하고 있습니다.위 경우 템플릿 문장 아래 오는 것이 class Vector 이므로 이 Vector 클래스에 대한 템플릿을 명시하는데, 만약에 밑에 오는 것이 함수일 경우 함수에 대한 템플릿이 됩니다. (밑에 함수 템플릿에 대해서도 설명하겠습니다).
참고로, 간혹
template <class T>
라고 쓰는 경우도 있는데, 이는 정확히 typename T 와 동일한 것 입니다. class T 라고 해서 T 자리에 꼭 클래스가 와야 하는 것이 아닙니다. 똑같이 int, char 등이 올 수 있습니다.
주의 사항
template <typename T> 와 template <class T> 는 정확히 같은 의미를 같지만 되도록이면 typename 키워드를 사용하기를 권장합니다.
왜 똑같은 템플릿에 두 개의 키워드를 정의하였냐였는지는 C++ 의 역사와 관련이 있습니다. C++ 을 처음 만들었던 Bjarne Stroustrup 은 처음에 template 의 인자로 class 키워드를 사용하였는데, 굳이 새로운 키워드를 만들고 싶지 않아서 였기 때문입니다.
하지만, 시간이 흘러서 C++ 위원회는 이로 인한 혼동을 막기 위해 (왜냐하면 class T 라 하면 T 자리에 꼭 클래스만 와야 하는 것 처럼 느껴지니까) typename 이라는 이름을 사용하기로 하였습니다. 물론, 이전 코드와의 호환을 위해 class 는 그대로 남겨 놓았지요. (자세한 내막은 여기 참조)
이렇게 정의한 템플릿의 인자에 값을 전달하기 위해서는
Vector<int> int_vec;
와 같이, <> 안에 전달하려는 것을 명시해주면 됩니다. 우리의 Vector 템플릿은 템플릿 인자로 타입을 받게 되는데, 위 경우 T 에 int 가 전달되게 됩니다.
여태까지는 인자로 특정한 '값' 혹은 '객체' 를 전달해왔지만 '타입' 그 자체를 전달한 적은 없었습니다. 하지만 템플릿을 통해 타입을 전달할 수 있게 됩니다.
Vector<int> // 혹은 Vector<std::string>
위와 같이 Vector 의 템플릿의 인자에 타입을 전달하게 되면, 컴파일러는 이것을 보고 실제 코드를 생성하게 됩니다. 예를 들어서, Vector <int> 의 경우
class Vector { int* data; int capacity; int length; public: // 어떤 타입을 보관하는지 typedef T value_type; // 생성자 Vector(int n = 1) : data(new int[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(int s) { if (capacity <= length) { int* temp = new int[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. int operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } ~Vector() { if (data) { delete[] data; } } };
T 가 정확히 int 로 치환된 위와 같은 코드를 찍어내겠지요. Vector<std::string> 의 경우 마찬가지로 T 가 string 으로 치환된 코드를 생성하게 됩니다.

위 사진 처럼, template 에 인자로 어떠한 타입을 전달하냐에 따라 int 를 저장하는 Vector 를 만들거나, string 을 저장하는 Vector 를 만들어낼 수 있는 것입니다. 마치 틀에 쇳물을 넣으면 쇠로 된 물건이 나오고, 구리물을 넣으면 구리로 된 물건이 나오는 것 처럼 말입니다.
Vector<int> int_vec;
따라서 위 코드는 Vector 의 T 가 int 로 치환된 클래스의 객체 int_vec 을 생성하게 되는 것이지요. 위와 같이 클래스 템플릿에 인자를 전달해서 실제 코드를 생성하는 것을 클래스 템플릿 인스턴스화 (class template instantiation) 라고 합니다.
템플릿이 인스턴스화 되지 않고 덩그러니 있다면 컴파일 시에 아무런 코드로 변환되지 않습니다. 템플릿은 반드시 인스턴스화 되어야지만 비로소 컴파일러가 실제 코드를 생성하게 되지요. 마치 틀 자체로는 아무런 의미가 없지만, 그 틀에 채워넣어 나오는 물건에 관심이 있는 것 처럼 말이지요.
위와 같이 템플릿에 사용자가 원하는 타입을 템플릿 인자로 전달하면, 컴파일러는 그 인자를 바탕으로 코드를 생성하여 이를 컴파일 하게 됩니다. 하지만, 간혹 일부 타입에 대해서는 다른 방식으로 처리해야 할 경우가 있습니다.
예를 들어서 bool 데이터를 보관하는 벡터를 생각해봅시다.
Vector<bool> int_vec;
사실 쉽게 생각해보면 그냥 위 처럼 템플릿 인자에 bool 을 전달하여 bool 을 저장하는 벡터로 사용할 수 도 있을 것입니다. 하지만 문제가 하나 있는데, C++ 에서 기본으로 처리하는 단위가 1 byte 라는 점입니다.
다시 말해 사실 bool 데이터 형은 1개 비트 만으로도 충분히 저장할 수 있지만, 8 비트를 사용해서 1개 bool 값을 저장해야 된다는 뜻이지요. 이는 엄청난 메모리 낭비가 아닐 수 없습니다. 따라서 우리는 Vector<bool> 에 대해서는 특별히 따로 처리해줘야만 합니다.
템플릿 특수화 (template specialization)
이와 같이 일부 경우에 대해서 따로 처리하는 것을 템플릿 특수화 라고 합니다. 템플릿 특수화는 다음과 같이 수행할 수 있습니다. 예를 들어서
template <typename A, typename B, typename C> class test {};
위와 같은 클래스 템플릿이 정의되어 있을 때, "아 나는 A 가 int 고 C 가 double 일 때 따로 처리하고 싶어!" 면,
template <typename B> class test<int, B, double> {};
와 같이 특수화 하고 싶은 부분에 원하는 타입을 전달하고 위에는 일반적인 템플릿을 쓰면 되겟지요. 만약에 B 조차도 특수화 하고 싶다면,
template <> class test<int, int, double> {};
와 같이 써주면 됩니다. 한 가지 중요한 점은, 전달하는 템플릿 인자가 없더라도 특수화 하고 싶다면 template<> 라도 남겨줘야 된다는 점입니다. 그렇다면 우리의 bool 벡터의 경우;
template <> class Vector<bool> { ... // 원하는 코드 }
와 같이 따로 처리해주면 되겠지요.
Vector<bool> 을 구현하기 위해서는 저는 평범한 int 배열을 이용할 것입니다. 1 개의 int 는 4 바이트 이므로, 32 개의 bool 데이터들을 한데 묶어서 저장할 수 있겠지요. 이를 통해서 원래 방식대로라면 bool 이 1 바이트로 저장되지만, 이렇게 하면 bool 을 1 비트로 정확히 표현할 수 있게 됩니다.
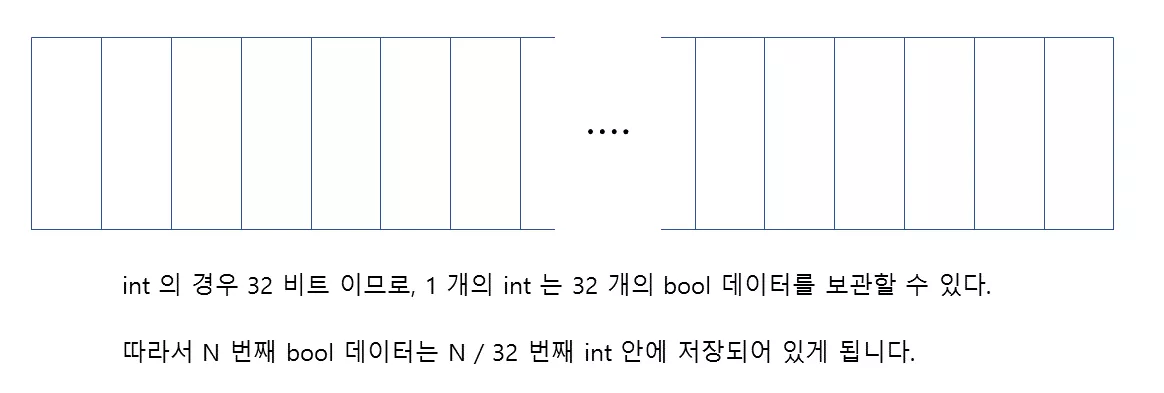
이렇게 한데 묶어서 저장하면 메모리 관련 측면에서는 효율이 매우 높아지지만, 이를 구현하는데는 조금 더 복잡해집니다. 왜냐하면 int 데이터에서 정확히 한 비트의 정보만 뽑아서 보여주어야 하기 때문이지요. 예를 들어서 N 번째 bool 데이터는 N / 32 번째 int 에 들어가 있고, 그 안에서 정확히 N % 32 번째 비트가 됩니다.
이와 같은 내용으로 구현을 하면 다음과 같습니다.
#include <iostream> #include <string> template <typename T> class Vector { T* data; int capacity; int length; public: // 어떤 타입을 보관하는지 typedef T value_type; // 생성자 Vector(int n = 1) : data(new T[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(T s) { if (capacity <= length) { T* temp = new T[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. T operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } ~Vector() { if (data) { delete[] data; } } }; template <> class Vector<bool> { unsigned int* data; int capacity; int length; public: typedef bool value_type; // 생성자 Vector(int n = 1) : data(new unsigned int[n / 32 + 1]), capacity(n / 32 + 1), length(0) { for (int i = 0; i < capacity; i++) { data[i] = 0; } } // 맨 뒤에 새로운 원소를 추가한다. void push_back(bool s) { if (capacity * 32 <= length) { unsigned int* temp = new unsigned int[capacity * 2]; for (int i = 0; i < capacity; i++) { temp[i] = data[i]; } for (int i = capacity; i < 2 * capacity; i++) { temp[i] = 0; } delete[] data; data = temp; capacity *= 2; } if (s) { data[length / 32] |= (1 << (length % 32)); } length++; } // 임의의 위치의 원소에 접근한다. bool operator[](int i) { return (data[i / 32] & (1 << (i % 32))) != 0; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { int prev = i - 1; int curr = i; // 만일 curr 위치에 있는 비트가 1 이라면 // prev 위치에 있는 비트를 1 로 만든다. if (data[curr / 32] & (1 << (curr % 32))) { data[prev / 32] |= (1 << (prev % 32)); } // 아니면 prev 위치에 있는 비트를 0 으로 지운다. else { unsigned int all_ones_except_prev = 0xFFFFFFFF; all_ones_except_prev ^= (1 << (prev % 32)); data[prev / 32] &= all_ones_except_prev; } } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } ~Vector() { if (data) { delete[] data; } } }; int main() { // int 를 보관하는 벡터를 만든다. Vector<int> int_vec; int_vec.push_back(3); int_vec.push_back(2); std::cout << "-------- int vector ----------" << std::endl; std::cout << "첫번째 원소 : " << int_vec[0] << std::endl; std::cout << "두번째 원소 : " << int_vec[1] << std::endl; Vector<std::string> str_vec; str_vec.push_back("hello"); str_vec.push_back("world"); std::cout << "-------- std::string vector -------" << std::endl; std::cout << "첫번째 원소 : " << str_vec[0] << std::endl; std::cout << "두번째 원소 : " << str_vec[1] << std::endl; Vector<bool> bool_vec; bool_vec.push_back(true); bool_vec.push_back(true); bool_vec.push_back(false); bool_vec.push_back(false); bool_vec.push_back(false); bool_vec.push_back(true); bool_vec.push_back(false); bool_vec.push_back(true); bool_vec.push_back(false); bool_vec.push_back(true); bool_vec.push_back(false); bool_vec.push_back(true); bool_vec.push_back(false); bool_vec.push_back(true); bool_vec.push_back(false); bool_vec.push_back(true); bool_vec.push_back(false); std::cout << "-------- bool vector ---------" << std::endl; for (int i = 0; i < bool_vec.size(); i++) { std::cout << bool_vec[i]; } std::cout << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
-------- int vector ---------- 첫번째 원소 : 3 두번째 원소 : 2 -------- std::string vector ------- 첫번째 원소 : hello 두번째 원소 : world -------- bool vector --------- 11000101010101010
와 같이 나옵니다.
unsigned int* data; int capacity; int length;
먼저 Vector<bool> 의 멤버 변수들 부터 살펴봅시다. 일단, int 배열로 unsigned int 를 사용하기로 하였습니다. 굳이 unsigned int 를 사용한 이유는 그냥 int 를 사용했을 때 shift 연산 시에 귀찮은 문제가 발생할 수 도 있기 때문입니다.
capacity 는 생성된 data 배열의 크기를 의미하고 length 는 실제 bool 데이터의 길이를 의미합니다. 즉 1 capacity 에 32 개의 bool 이 들어갈 수 있게 되는 것이지요. (int 가 32 비트라 생각하면)
// 맨 뒤에 새로운 원소를 추가한다. void push_back(bool s) { if (capacity * 32 <= length) { unsigned int* temp = new unsigned int[capacity * 2]; for (int i = 0; i < capacity; i++) { temp[i] = data[i]; } for (int i = capacity; i < 2 * capacity; i++) { temp[i] = 0; } delete[] data; data = temp; capacity *= 2; } if (s) { data[length / 32] |= (1 << (length % 32)); } length++; }
다음으로 push_back 함수를 살펴보도록 합시다. 일단 윗 부분은 동일합니다. 만일 현재 길이가 capacity 를 초과하게 되면 현재 크기의 2 배로 새로 배열을 만들어서 복사하게 됩니다. 그리고 기본적으로 배열 전체를 0 으로 초기화 하기 때문에 기본적으로 false 로 설정되어 있다고 보시면 됩니다.
if (s) { data[length / 32] |= (1 << (length % 32)); }
따라서 위 처럼 만일 true 를 추가하였을 때에만 해당 비트를 true 로 바꿔주면 됩니다. 어떤 비트에 1 을 OR 연산하게 되면 그 비트는 무조건 1 이 됩니다. 그리고 0 을 OR 연산하게 되면 그 비트의 값은 그대로 보존이 되지요. 따라서 OR 연산은 특정 비트에만 선택적으로 1로 바꾸는데 매우 좋은 연산입니다. 아래 그림을 보면 이해가 잘 되실 것입니다. 주변 나머지 비트들의 값은 보존하면서 특정 비트만 1 로 바꿔줍니다.
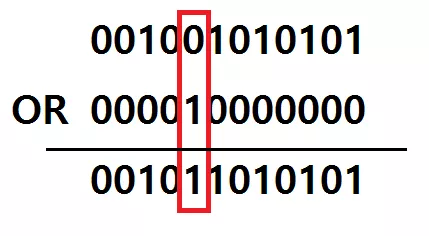
위 경우에도 1 << (length % 32) 을 통해서 정확히 length % 32 번째 비트만 1 로 바꾼 뒤, OR 연산을 해서 해당 int 의 자리를 true 로 만들어 줄 수 있습니다.
// 임의의 위치의 원소에 접근한다. bool operator[](int i) { return (data[i / 32] & (1 << (i % 32))) != 0; }
그렇다면 임의의 위치에 접근하는 것은 어떨까요.
이번에는 거꾸로 AND 연산을 통해 해당 값을 가져올 수 있습니다. 어떤 비트에 0 을 AND 하게 되면 그 비트는 무조건 0 이 되고, 1 을 AND 연산 하게 되면 해당 비트가 1 이여야지만 1 이 됩니다. 즉, 1 을 AND 하게 되면 해당 비트의 값이 무엇인지 알아낼 수 있는 것입니다. 아래 그림을 보면 더 이해하기 쉽습니다.
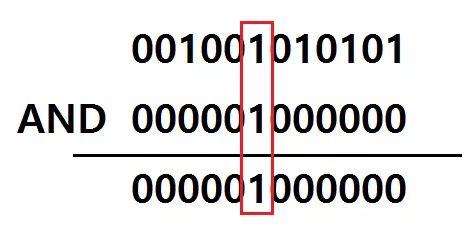
data[i / 32] & (1 << (i % 32))
따라서 위 작업을 수행하게 되면 해당 위치에 있는 비트가 1 일 때 에만 저 값이 0 이 아니게 되고 0 이면 저 값 전체가 0 이 됩니다.
// x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { int prev = i - 1; int curr = i; // 만일 curr 위치에 있는 비트가 1 이라면 // prev 위치에 있는 비트를 1 로 만든다. if (data[curr / 32] & (1 << (curr % 32))) { data[prev / 32] |= (1 << (prev % 32)); } // 아니면 prev 위치에 있는 비트를 0 으로 지운다. else { unsigned int all_ones_except_prev = 0xFFFFFFFF; all_ones_except_prev ^= (1 << (prev % 32)); data[prev / 32] &= all_ones_except_prev; } } length--; }
마지막으로 remove 함수를 살펴봅시다.
사실 이전 버전에서는 그냥 오른쪽 원소를 왼쪽으로 쭈르륵 덮어 씌어나가는 방식으로 간단히 만들 수 있었지만 이 bool 버전의 경우 그 '왼쪽' 과 '오른쪽' 원소를 읽어내는거 자체가 꽤나 복잡하므로 간단하게는 구현하기 힘듧니다.
// 만일 curr 위치에 있는 비트가 1 이라면 // prev 위치에 있는 비트를 1 로 만든다. if (data[curr / 32] & (1 << (curr % 32))) { data[prev / 32] |= (1 << (prev % 32)); }
그래도 일단 특정 비트를 1 로 만드는 것은 간단합니다. 이전에도 하였듯이, OR 을 수행해주면 됩니다.
// 아니면 prev 위치에 있는 비트를 0 으로 지운다. else { unsigned int all_ones_except_prev = 0xFFFFFFFF; all_ones_except_prev ^= (1 << (prev % 32)); data[prev / 32] &= all_ones_except_prev; }
그렇다면 왼쪽 비트가 0 일 때 오른쪽 비트를 0 으로 만드는 작업은 어떻게 할까요? (왼쪽이 더 나중 원소이므로 거꾸로 생각해야 한다). 앞서 AND 연산의 경우 1 을 AND 하게 되면 원래 비트가 보존되고, 0 을 AND 하면 0 이 된다고 하였습니다. 따라서, 우리가 해야할 일은 원하는 자리의 비트만 0 이고 나머지는 1 인 것을 AND 해주면 됩니다. 그 과정을 수행하는 부분이 아래와 같습니다.
unsigned int all_ones_except_prev = 0xFFFFFFFF; all_ones_except_prev ^= (1 << (prev % 32));
all_ones_except_prev 는 0 으로 지우려고 하는 위치만 0 이고 나머지 부분은 1 인 값 입니다. 참고로 기억하는지는 모르겠지만, ^ 는 XOR 연산자로, 두 비트가 같으면 0, 다르면 1 이되는 연산 입니다 (덧셈을 생각하시면 됩니다). 따라서 0xFFFFFFFF 는 모든 비트가 1 인 int 인데, XOR 연산을 통해서 해당 비트만 0 으로 바꿔줍니다.
그 후에 AND 연산을 하게 되면 해당 비트만 0 으로 지워버릴 수 있게 되지요.
실제로, C++ 표준 라이브러리에서 vector 를 지원을 하는데, 그 구현을 살펴보면 위 처럼 bool 일 때만 따로 특수화 시켜서 처리하고 있습니다. C++ 표준 라이브러리의 vector 는 나중 강좌에서 다루도록 하겠습니다.
템플릿 특수화를 통해 템플릿 인자의 값이 특정 값일 때 따로 처리하는 방식에 대해 알아보았습니다.
함수 템플릿 (Function template)
이번에는 클래스 템플릿이 아닌 함수 템플릿에 대해 알아보도록 하겠습니다.
#include <iostream> #include <string> template <typename T> T max(T& a, T& b) { return a > b ? a : b; } int main() { int a = 1, b = 2; std::cout << "Max (" << a << "," << b << ") ? : " << max(a, b) << std::endl; std::string s = "hello", t = "world"; std::cout << "Max (" << s << "," << t << ") ? : " << max(s, t) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
Max (1,2) ? : 2 Max (hello,world) ? : world
와 같이 나옵니다.
template <typename T> T max(T& a, T& b) { return a > b ? a : b; }
위 부분에서 템플릿 함수를 정의하고 있습니다. 클래스 템플릿과 마찬가지로, 위 함수도 인스턴스화 되기 전 까지는 컴파일 시에 아무런 코드로 변환되지 않습니다.
std::cout << "Max (" << a << "," << b << ") ? : " << max(a, b) << std::endl;
실제로 위 템플릿 함수가 인스턴스화 되는 부분은 바로 위 코드에서 max(a, b) 가 호출되는 부분입니다. 신기하게도, 클래스를 인스턴스화 했을 때 와는 다르게 <> 하는 부분이 없습니다. 원래 대로라면
max<int>(a, b)
이렇게 했었겠지요. 하지만 C++ 컴파일러는 생각보다 똑똑해서, a 와 b 의 타입을 보고 알아서 max (a, b) 를 max<int>(a, b) 로 인스턴스화 해줍니다.
std::cout << "Max (" << s << "," << t << ") ? : " << max(s, t) << std::endl;
string 의 경우도 마찬가지 입니다. C++ 컴파일러가 알아서 max<string>(s, t) 로 생각해서 인스턴스화 해줍니다.
그렇다면 다음 함수를 살펴봅시다.
template <typename Cont> void bubble_sort(Cont& cont) { for (int i = 0; i < cont.size(); i++) { for (int j = i + 1; j < cont.size(); j++) { if (cont[i] > cont[j]) { cont.swap(i, j); } } } }
위 함수는 임의의 컨테이너를 받아서 이를 정렬해 주는 함수 입니다 (사실 위 함수는 소위 말하는 거품 정렬 (버블소트) 방식을 사용하는데 매우 느립니다. 여러분들이 더 빠른 정렬 알고리즘(퀵소트, 등등)으로 구현해보세요!). 컨테이너란 쉽게 생각해서 데이터를 보관하는 것이라 생각하면 되는데, 앞서 소개하였던 Vector 도 하나의 예가 될 수 있습니다.
물론, 저 함수가 작동을 하려면 컨테이너에 size 함수와, swap 함수, 그리고 [ ] 연산자가 정의되어 있어야 겠지요.
#include <iostream> template <typename T> class Vector { T* data; int capacity; int length; public: // 어떤 타입을 보관하는지 typedef T value_type; // 생성자 Vector(int n = 1) : data(new T[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(int s) { if (capacity <= length) { int* temp = new T[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. T operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } // i 번째 원소와 j 번째 원소 위치를 바꾼다. void swap(int i, int j) { T temp = data[i]; data[i] = data[j]; data[j] = temp; } ~Vector() { if (data) { delete[] data; } } }; template <typename Cont> void bubble_sort(Cont& cont) { for (int i = 0; i < cont.size(); i++) { for (int j = i + 1; j < cont.size(); j++) { if (cont[i] > cont[j]) { cont.swap(i, j); } } } } int main() { Vector<int> int_vec; int_vec.push_back(3); int_vec.push_back(1); int_vec.push_back(2); int_vec.push_back(8); int_vec.push_back(5); int_vec.push_back(3); std::cout << "정렬 이전 ---- " << std::endl; for (int i = 0; i < int_vec.size(); i++) { std::cout << int_vec[i] << " "; } std::cout << std::endl << "정렬 이후 ---- " << std::endl; bubble_sort(int_vec); for (int i = 0; i < int_vec.size(); i++) { std::cout << int_vec[i] << " "; } std::cout << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
정렬 이전 ---- 3 1 2 8 5 3 정렬 이후 ---- 1 2 3 3 5 8
와 같이 나옵니다.
참고로 기존에 만들었던 Vector 에는 swap 함수가 없어서 새로 추가하였습니다.
template <typename Cont> void bubble_sort(Cont& cont) { for (int i = 0; i < cont.size(); i++) { for (int j = i + 1; j < cont.size(); j++) { if (cont[i] > cont[j]) { cont.swap(i, j); } } } }
위 부분을 보면 정렬 함수를 템플릿으로 구현한 것을 볼 수 있습니다.
bubble_sort(int_vec);
와 같이 위 함수를 호출한다면 컴파일러는 인자로 전달된 객체의 타입을 보고 알아서 인스턴스화 한 뒤에 컴파일 하게 되지요. 위 경우에 int_vec 이 Vector<int> 타입 이므로, Cont 에 Vector<int> 가 전달 될 것입니다.
다만 한 가지 중요한 사실은,
for (int i = 0; i < cont.size(); i++) {
에서나,
if (cont[i] > cont[j]) { cont.swap(i, j);
에서 size(), operator[], swap() 등이 사용되었다는 것입니다. 만약에 Cont 로 전달된 타입에 저러한 것들이 정의가 되어 있지 않다면 어떨까요? 예를 들어서
struct dummy {}; dummy a; bubble_sort(a);
를 하게 된다면
컴파일 오류
error C2039: 'size': is not a member of 'dummy' ...
컴파일 시에, 위와 같은 저 클래스에서 멤버 함수나 변수들을 찾을 수 없다는 오류들을 뿜어내게 됩니다. 당연한 이야기지만 이와 같이 템플릿으로 발생되는 오류는 프로그램이 실행되었을 때가 아니라 컴파일 할 때 발생한 다는 사실입니다. 왜냐하면 컴파일 시에 모든 템플릿을 실제 코드로 변환하여 실행하기 때문이지요.
재미있게도, 이와 같이 컴파일 시에 모든 템플릿들이 인스턴스화 되다는 사실을 가지고 또 여러가지 흥미로운 코드를 짤 수 있는데 이러한 방식을 템플릿 메타프로그래밍 (template metaprogramming) 이라고 합니다. 자세한 내용은 나중 강좌들에서 다루도록 하겠습니다.
그런데 위 bubble_sort 함수에서는 한 가지 부족한 점이 있습니다. 만약에, 정렬 순서를 역순으로 하고 싶다면 어떨까요? 위는 오름 차순으로 정렬하였지만, 간혹 내림 차순으로 정렬을 하고 싶을 수 도 있습니다. 아니면 아예 다른 기준으로 정렬을 할 수 도 있겠지요. 이를 위해서라면 크게 세 가지 방법이 있습니다.
bubble_sort2를 만들어서 부등호 방향을 반대로 바꿔준다.operator>를 오버로딩해서 원하는 방식으로 만들어준다.cont[i]와cont[j]의 비교를>로 하지 말고 특정 함수에 넣어서 전달한다.
첫번째 방법은 C 를 배우는 단계에서나 적합한 방법입니다. 여러분은 C++ 를 배우고 있으니 더 나은 방법을 생각해야겠지요? 두번째 방법은 여러분들이 만든 객체를 사용할 때 적용할 수 있는 방법입니다. 예를 들어서,
struct customClass { // .. bool operator<(const customClass& c) { // Do something } }; Vector<customClass> a; bubble_sort(a);
와 같이 여러분이 직접 정의한 클래스에 대해 operator< 를 오버로딩 할 수 있다면 원하는 방식으로 정렬을 수행할 수 있겠지요. 하지만 위 처럼 기본적으로 operator< 를 오버로딩 할 수 없는 상황이라면 어떨까요? 예를 들어서 int 나 string 은 이미 내부적으로 operator< 가 정의되어 있기 때문에 이를 따로 오버로딩을 할 수 없습니다.
그렇다면 3 번째 방법은 어떨까요?
함수 객체(Function Object - Functor) 의 도입
그럼 다음과 같은 함수를 생각해봅시다.
template <typename Cont, typename Comp> void bubble_sort(Cont& cont, Comp& comp) { for (int i = 0; i < cont.size(); i++) { for (int j = i + 1; j < cont.size(); j++) { if (!comp(cont[i], cont[j])) { cont.swap(i, j); } } } }
위 함수는 기존의 bubble_sort 와는 달리 아예 Comp 라는 클래스를 템플릿 인자로 받고, 함수 자체도 Comp 객체를 따로 받습니다. 그렇다면 이 comp 객체가 무슨 일을 하냐면;
if (!comp(cont[i], cont[j])) {
이 if 문에서 마치 함수를 호출하는 것 처럼 사용되는데, cont[i] 와 cont[j] 를 받아서 내부적으로 크기 비교를 수행한 뒤에 그 결과를 리턴하고 있습니다.
한 가지 중요한 사실은 comp 는 함수가 아니라 객체 이고, Comp 클래스에서 () 연산자를 오버로딩한 버전입니다. 자세한 내용은 아래 전체 코드를 보면서 설명하겠습니다.
#include <iostream> template <typename T> class Vector { T* data; int capacity; int length; public: // 어떤 타입을 보관하는지 typedef T value_type; // 생성자 Vector(int n = 1) : data(new T[n]), capacity(n), length(0) {} // 맨 뒤에 새로운 원소를 추가한다. void push_back(int s) { if (capacity <= length) { int* temp = new T[capacity * 2]; for (int i = 0; i < length; i++) { temp[i] = data[i]; } delete[] data; data = temp; capacity *= 2; } data[length] = s; length++; } // 임의의 위치의 원소에 접근한다. T operator[](int i) { return data[i]; } // x 번째 위치한 원소를 제거한다. void remove(int x) { for (int i = x + 1; i < length; i++) { data[i - 1] = data[i]; } length--; } // 현재 벡터의 크기를 구한다. int size() { return length; } // i 번째 원소와 j 번째 원소 위치를 바꾼다. void swap(int i, int j) { T temp = data[i]; data[i] = data[j]; data[j] = temp; } ~Vector() { if (data) { delete[] data; } } }; template <typename Cont> void bubble_sort(Cont& cont) { for (int i = 0; i < cont.size(); i++) { for (int j = i + 1; j < cont.size(); j++) { if (cont[i] > cont[j]) { cont.swap(i, j); } } } } template <typename Cont, typename Comp> void bubble_sort(Cont& cont, Comp& comp) { for (int i = 0; i < cont.size(); i++) { for (int j = i + 1; j < cont.size(); j++) { if (!comp(cont[i], cont[j])) { cont.swap(i, j); } } } } struct Comp1 { bool operator()(int a, int b) { return a > b; } }; struct Comp2 { bool operator()(int a, int b) { return a < b; } }; int main() { Vector<int> int_vec; int_vec.push_back(3); int_vec.push_back(1); int_vec.push_back(2); int_vec.push_back(8); int_vec.push_back(5); int_vec.push_back(3); std::cout << "정렬 이전 ---- " << std::endl; for (int i = 0; i < int_vec.size(); i++) { std::cout << int_vec[i] << " "; } Comp1 comp1; bubble_sort(int_vec, comp1); std::cout << std::endl << std::endl << "내림차순 정렬 이후 ---- " << std::endl; for (int i = 0; i < int_vec.size(); i++) { std::cout << int_vec[i] << " "; } std::cout << std::endl; Comp2 comp2; bubble_sort(int_vec, comp2); std::cout << std::endl << "오름차순 정렬 이후 ---- " << std::endl; for (int i = 0; i < int_vec.size(); i++) { std::cout << int_vec[i] << " "; } std::cout << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
정렬 이전 ---- 3 1 2 8 5 3 내림차순 정렬 이후 ---- 8 5 3 3 2 1 오름차순 정렬 이후 ---- 1 2 3 3 5 8
와 같이 나옵니다.
struct Comp1 { bool operator()(int a, int b) { return a > b; } }; struct Comp2 { bool operator()(int a, int b) { return a < b; } };
일단 위 두 클래스를 살펴보도록 합시다. Comp1 과 Comp2 모두 아무 것도 하지 않고 단순히 operator() 만 정의하고 있습니다. 그리고 이 Comp1 과 Comp2 객체들은 bubble_sort 함수 안에서
if (!comp(cont[i], cont[j])) {
마치 함수인양 사용되지요. 이렇게, 함수는 아니지만 함수 인 척을 하는 객체를 함수 객체 (Function Object), 혹은 줄여서 Functor 라고 부릅니다. 이 Functor 덕분에, bubble_sort 함수 내에서 두 객체간의 비교를 사용자가 원하는 대로 할 수 있게 되지요.
따라서 사용자들은 입맛에 맞게, 보통의 < 연산자로 비교를 수행하는
template <typename Cont> void bubble_sort(Cont& cont)
위 bubble_sort 함수를 사용하거나;
template <typename Cont, typename Comp> void bubble_sort(Cont& cont, Comp& comp)
특수한 경우에 따로 비교 하는 것을 직접 수행하고 싶은 경우에 Comp 객체를 받아서 비교를 수행하는 새로운 bubble_sort 함수를 사용할 수 있습니다.
물론
bubble_sort(int_vec, comp1);
를 했다면 두 번째 버전으로 템플릿 인스턴스화 되서 함수가 호출되고,
bubble_sort(int_vec);
그냥 위 처럼 한다면 첫 번째 버전으로 템플릿 인스턴스화 되서 함수가 호출되겠지요.
실제로, C++ 표준 라이브러리의 sort 함수를 살펴보아도 비교 클래스를 받지 않는
template <class RandomIt> void sort(RandomIt first, RandomIt last);
와
template <class RandomIt, class Compare> void sort(RandomIt first, RandomIt last, Compare comp);
비교 클래스를 받는 위 버전으로 구성되어 있습니다. (저 함수의 인자들에 대해서는 나중 강좌에서 자세히 다룰 테니 지금은 넘어가셔도 됩니다!)
이와 같이 비교 클래스를 받아서 원하는 비교 작업을 수행할 수 있게 됩니다. 만약에 C 였다면 위 sort 함수를 어떻게 만들었을 지 생각해봅시다. 일단 원하는 클래스를 받는 다는 생각 자체가 불가능하기 때문에 (template 이 없으니까) functor 는 꿈도 못 꾸었겠지요. 대신에, 비교 작업을 수행하는 함수의 포인터를 받아서 이를 처리하였을 것입니다.
그렇다면 뭐가 더 나은 방법일까요? Functor? 아니면 구닥다리 함수 포인터?
이미 예상하셨겠지만, Functor 를 사용하는것이 여러 모로 훨씬 편리한 점이 많습니다. 일단, 클래스 자체에 여러가지 내부 state 를 저장해서 비교 자체가 복잡한 경우에도 손쉽게 사용자가 원하는 방식으로 만들어낼 수 있습니다. 뿐만 아니라, 함수포인터로 함수를 받아서 처리한다면 컴파일러가 최적화를 할 수 없지만, Functor 를 넘기게 된다면 컴파일러가 operator() 자체를 인라인화 시켜서 매우 빠르게 작업을 수행할 수 있습니다.
타입이 아닌 템플릿 인자 (non-type template arguments)
한 가지 재미있는 점은 템플릿 인자로 타입만 받을 수 있는 것이 아닙니다. 예를 들어 아래와 같은 코드를 보실까요.
#include <iostream> template <typename T, int num> T add_num(T t) { return t + num; } int main() { int x = 3; std::cout << "x : " << add_num<int, 5>(x) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
x : 8
와 같이 나옵니다. 먼저 add_num 함수의 정의 부분 부터 살펴봅시다.
template <typename T, int num> T add_num(T t) { return t + num; }
template 의 인자로 T 를 받고, 추가적으로 마치 함수의 인자 처럼 int num 을 또 받고 있습니다. 해당 템플릿 인자들은 add_num 함수를 호출할 때 <> 를 통해 전달하는 인자들이 들어가게 됩니다. 우리의 예제의 경우
add_num<int, 5>(x)
위와 같이 T 에 int 를, num 에 5 를 전달하였으므로 생성되는 add_num 함수는 아래와 같습니다.
int add_num(int t) { return t + 5; }
참고로 만약에 add_num 에 템플릿 인자 <> 를 지정하지 않았더라면 아래와 같은 컴파일 타임 오류가 발생하게 됩니다.
컴파일 오류
test2.cc: In function ‘int main()’:
test2.cc:10:35: error: no matching function for call to ‘add_num(int&)’
std::cout << "x : " << add_num(x) << std::endl;
^
test2.cc:4:3: note: candidate: template<class T, int num> T add_num(T)
T add_num(T t) {
^~~~~~~
test2.cc:4:3: note: template argument deduction/substitution failed:
test2.cc:10:35: note: couldn't deduce template parameter ‘num’
std::cout << "x : " << add_num(x) << std::endl;
왜냐하면 상식적으로 컴파일러가 num 에 뭐가 들어가는지 알길이 없이 때문이죠. 따라서 위 처럼 num 의 값을 결정할 수 없다고 불만을 제시하는 오류가 발생하게 됩니다.
한 가지 중요한 점은 템플릿 인자로 전달할 수 있는 타입들이 아래와 같이 제한적입니다. (자세한 내용은 여기 참조)
정수 타입들 (
bool,char,int,long등등). 당연히float과double은 제외포인터 타입
enum타입std::nullptr_t(널 포인터)
타입이 아닌 템플릿 인자를 가장 많이 활용하는 예시는 컴파일 타임에 값들이 정해져야 하는 것들이 되겠습니다. 대표적인 예시로 배열을 들 수 있겠지요. C 에서의 배열의 가장 큰 문제점은 함수에 배열을 전달할 때 배열의 크기에 대한 정보를 잃어버린다는 점입니다.
하지만 템플릿 인자로 배열의 크기를 명시한다면 (어차피 배열의 크기는 컴파일 타임에 정해지는 것이니까), 이 문제를 완벽하게 해결 할 수 있습니다. 이와 같은 기능을 가진 배열을 C++ 11 부터 제공되는 std::array 를 통해 사용할 수 있습니다.
#include <iostream> #include <array> int main() { // 마치 C 에서의 배열 처럼 {} 을 통해 배열을 정의할 수 있다. // {} 문법은 16 - 1 강에서 자세히 다루므로 여기서는 그냥 이렇게 // 쓰면 되는구나 하고 이해하고 넘어가면 됩니다. std::array<int, 5> arr = {1, 2, 3, 4, 5}; // int arr[5] = {1, 2, 3, 4, 5}; 와 동일 for (int i = 0; i < arr.size(); i++) { std::cout << arr[i] << " "; } std::cout << std::endl; }
성공적으로 컴파일 하였으면
실행 결과
1 2 3 4 5
와 같이 나옵니다. 사용법은 C 에서의 배열과 동일합니다.
std::array<int, 5> arr = {1, 2, 3, 4, 5};
위 처럼 배열의 원소들의 타입과 (int) 크기 (5) 를 템플릿 인자로 명시한 뒤에, 초기화만 해주면 됩니다. 그리고 마치 C 에서 배열을 정의할 때 처럼 {} 를 이용해서 생성하면 됩니다. 참고로 {} 는 유니폼 초기화(uniform initialization) 이라 불리는 C++ 11 에서 추가된 개념인데, 지금은 그냥 std::array 의 생성자를 호출하는 또 하나의 방법이라 생각하시면 되고 나중에 16 - 1 강에서 좀 더 자세히 다룹니다.
한 가지 재미있는 점은 이 arr 은 런타임에서 동적으로 크기가 할당되는 것이 아니라는 점입니다. 마치 배열 처럼 컴파일 시에 int 5 개를 가지는 메모리를 가지고 스택 에 할당됩니다.
또한 중요한 점으로 이 배열을 함수에 전달하기 위해서는 그냥 std::array 를 받는 함수를 만들면 안됩니다. std::array<int, 5> 자체가 하나의 타입이기 때문에;
#include <iostream> #include <array> void print_array(const std::array<int, 5>& arr) { for (int i = 0; i < arr.size(); i++) { std::cout << arr[i] << " "; } std::cout << std::endl; } int main() { std::array<int, 5> arr = {1, 2, 3, 4, 5}; print_array(arr); }
성공적으로 컴파일 하였다면
실행 결과
1 2 3 4 5
와 같이 나옵니다.
void print_array(const std::array<int, 5>& arr) {
문제는 각 array 크기 별로 함수를 만들어줘야 합니다. 하지만 우리는 알고 있지요. 여기서도 역시 템플릿을 쓸 수 있다는 것을 말이죠. 따라서 그냥
#include <iostream> #include <array> template <typename T> void print_array(const T& arr) { for (int i = 0; i < arr.size(); i++) { std::cout << arr[i] << " "; } std::cout << std::endl; } int main() { std::array<int, 5> arr = {1, 2, 3, 4, 5}; std::array<int, 7> arr2 = {1, 2, 3, 4, 5, 6, 7}; std::array<int, 3> arr3 = {1, 2, 3}; print_array(arr); print_array(arr2); print_array(arr3); }
성공적으로 컴파일 하였다면
실행 결과
1 2 3 4 5 1 2 3 4 5 6 7 1 2 3
와 같이 잘 나옵니다.
디폴트 템플릿 인자
마지막으로 살펴볼 점은 함수에 디폴트 인자를 지정할 수 있는 것처럼 템플릿도 디폴트 인자를 지정할 수 있습니다. 예를 들어서 이전에 만들었던 add_num 함수를 다시 살펴봅시다.
#include <iostream> template <typename T, int num = 5> T add_num(T t) { return t + num; } int main() { int x = 3; std::cout << "x : " << add_num(x) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
x : 8
와 같이 나옵니다. 템플릿 디폴트 인자는 함수 디폴트 인자랑 똑같이 인자 뒤에 = (디폴트 값) 을 넣어주면 됩니다.
template <typename T, int num = 5>
위 경우 num 에 디폴트로 5 가 전달됩니다. 따라서
std::cout << "x : " << add_num(x) << std::endl;
위 문장은 마치 add_num<int, 5> 를 한 것과 동일합니다. (참고로 int 는 컴파일러가 자동으로 추론해주었습니다.)
타입 역시 디폴트로 지정이 가능합니다. 예를 들어서 아래와 같은 min 함수를 생각해봅시다.
template <typename T, typename Comp> T Min(T a, T b) { Comp comp; if (comp(a, b)) { return a; } return b; }
Min 함수는 임의의 두 원소를 받아서 작은 원소를 리턴합니다. 이 때 이 원소들을 어떻게 비교할지는 Comp 라는 객체가 이를 수행합니다.
물론 우리는 int 와 같이 간단한 애들은 그냥 < 를 사용해서 대소 비교를 하면 되지만 일반적인 객체들에 대해서도 모두 동작하게 하려면 따로 두 원소를 비교하는 Comp 라는 클래스가 필요합니다.
예를 들어서 int 간의 대소 비교를 위해서는
template <typename T> struct Compare { bool operator()(const T& a, const T& b) const { return a < b; } }; int a = 3, b = 4; std::cout << "min : " << Min<int, Compare<int>>(a, b);
와 같이 Compare 타입을 굳이 써서 전달해줘야 하지요. 하지만 디폴트 템플릿 인자를 이용하면 아래 처럼 매우 간단하게 사용할 수 있게 됩니다.
#include <iostream> #include <string> template <typename T> struct Compare { bool operator()(const T& a, const T& b) const { return a < b; } }; template <typename T, typename Comp = Compare<T>> T Min(T a, T b) { Comp comp; if (comp(a, b)) { return a; } return b; } int main() { int a = 3, b = 5; std::cout << "Min " << a << " , " << b << " :: " << Min(a, b) << std::endl; std::string s1 = "abc", s2 = "def"; std::cout << "Min " << s1 << " , " << s2 << " :: " << Min(s1, s2) << std::endl; }
성공적으로 컴파일 하였다면
실행 결과
Min 3 , 5 :: 3 Min abc , def :: abc
와 같이 잘 나옵니다. 이들 모두 Comp 로 디폴트 타입인 Compare<T> 가 전달되어서 < 를 통해 비교를 수행하였습니다.
이번 강좌는 내용이 상당히 길었는데요, 이상으로 C++ 템플릿 첫 번째 강좌를 마치도록 하겠습니다. 그 만큼 템플릿의 위력이 강력하다는 뜻이지요. 다음 강좌에서는 템플릿이 C++ 에게 하사한 새로운 패러다임의 세계로 떠나볼 것입니다.
생각 해보기
문제 1
template 을 사용해서 이전에 만들어 놓았던 Excel 프로젝트 코드를 깔끔하게 만들어보세요. 아마 10 배는 깔끔해질 것입니다 :) (난이도 : 下)
문제 2
위 Vector 로 2차원, 3차원 배열 등을 똑같이 만들어낼 수 있을까요? (난이도 : 下)
문제 3
위에서 컴파일러가 마법 처럼 템플릿 인자에 타입을 정해준다고 하지만 사실은 어떤 타입으로 추측할지 결정하는 일련의 규칙들이 있습니다. 자세한 내용은 여기를 참고해주세요

댓글을 불러오는 중입니다..